
Analyzing the metadata in a document is a fairly straightforward process. However, analyzing the document itself is a little messier.
Document analysis is nothing new- people have been programming computers to refine full text analysis since the days when full text first started to appear. As hard drive space became cheaper and computers become more powerful, new documents began to be stored and new ways to analyze them were developed. In Information Storage and Retrieval, Korfhage mentions several of these methods, but things have evolved quite a bit since then. Besides the methods mentioned below, specialized retrieval systems such as face recognition used in law enforcement have been developed, but I will focus on a few technologies available to the general public.
Text Analysis
Text analysis in documents has come a long way since the inclusion of the first full text documents in databases. Search engines have become quite good at parsing the full text of web pages, as well as using hypertext and other measures to determine what a page is about. With the advent off more and more full electronic text, scholars have started to study ways to use text analysis on literary works. One such project is the Mellon funded MONK project. Sites are starting to work text analysis into their search and browsing features as well.
The Willa Cather Archive offers a feature to perform in depth text analysis on all of Cather’s books using a program called TokenX. This process is different than simply searching for a term because you can do new things, such as compare the use of words across books and contextualize the words for the user. These kinds of analyses allow scholars new ways to analyze literature.
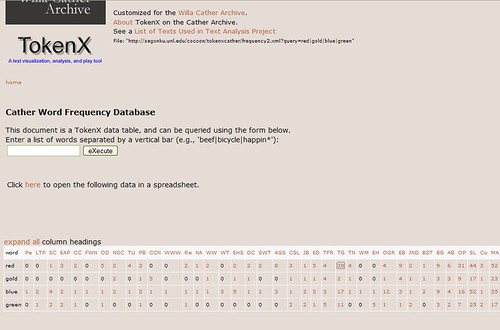
Cather Archive text analysis powered by TokenX, search results view.

Cather Archive text analysis powered by TokenX, words in context view.
Another now common way to analyze documents is to create a word cloud of common words. Word clouds are commonly made up of user entered metadata such as tags, and are less commonly used with entire documents. The reason why is fairly obvious when one sees such a cloud- words like “a,” “an,” “the,” and “that” end up being the largest words in the cloud because they are the most common. However, a word cloud can be a useful way to browse even full text documents. This can be achieved by carefully filtering out words that do not add meaning to the cloud. The website “The Mountain Meadows Massacre in public discourse” does this in one of its visualizations, offering a view of common words used in articles about the Mountain Meadows Massacre . Another site that uses this technique is a search engine called Quintura (Fig. 15). Quintura analyzes the results from a web search and creates a word cloud of corresponding terms. Users can click on words to add or subtract them from a search. This may be more intuitive for users who don’t know how to use an advanced search.
 |
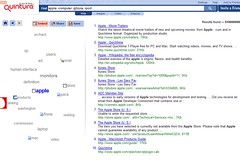 |
| “The Mountain Meadows Massacre in public discourse” word cloud. | Quintura search engine. |
Multimedia Document Analysis
Although text analysis has been around for a while, it is only recently that computers have been able to analyze image and sound documents. It is not that such a search is impossible. In fact, Korfhage reported work was already beginning on such analysis in 1997, but it is extremely computer intensive and complex. As Korfhage notes, the transformations something might go through are enormous- a picture of a bridge can be from above, below, from the side, or on the bridge. It might be a sketch or a photograph. Also, there are hundreds of types of bridges (p. 249). Asking a computer to identify a bridge in an image is still a long way off and may never happen. However, other kinds of image analysis are possible and even easy using computers.
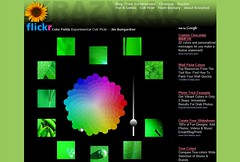
Color is one thing that is easy enough to analyze using a computer. The computer can select areas of a picture, average the colors, and match those colors up to a user provided hue. This allows for some interesting image analysis that aids both browsing and finding. One such site is called Flickr Colr Pickr . The navigation in this site is simple: choose a color from the color wheel, and the engine returns results that match the color. Another search that uses the Flickr API is called Retrievr, which allows for an even more complex query: it lets the user draw a picture to return pictures that resemble the drawing. This may work well when looking for photos of a sunset or the ocean, and less well for images of a dog. Retreivr is based on research by Chuck Jacobs, Adam Finkelstein and David Salesin, who created an algorithm which is “simple, requires very little storage overhead for the database of signatures, and is fast” (Jacobs, Finkelstein, & Salesin, 1995, p. 277).
 |
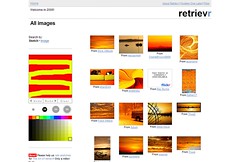 |
| Flickr Color Fields allows searching Flickr photos by color. | Retrievr matches photos to a drawing. |
The above means of finding photos work well for browsing, but not as well for finding. One application that could prove very useful for finding is demonstrated by Dave Pattern (based on earlier experiments by Tim Hodson) (clarified thanks to Tim’s comment below) in an experimental site which lets you search for a book by color. Tim Hodson explained the usefulness of such a feature in a blog post. Imagine a patron asking “I heard about a book three months ago. I can’t remember who wrote it or what it was called, but it was blue” (Hodson, 2008, para. 3). Pattern goes on to describe the process for searching book covers in the same way Retreivr searches Flickr images “The search works by comparing the hex colours of the 8×8 version of the search image with the corresponding pixels of the book covers. Each book cover then gets ranked by how well it matches the search image” (Pattern, 2007, para. 8). Etsy has yet another fun way to search for products with its Colors search. Pick a color and Etsy will show you photos of products whose colors match your request. Although this isn’t a perfect method, it is an innovative way to search products.
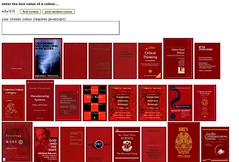 |
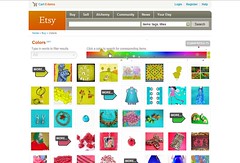 |
| Dave Pattern’s demo of a book search by color. | Etsy Colors. |
One website, called like.com, uses several methods to help the user find a good result. Like.com might be one of the first applications of research performed by Wei-Ying Ma1 and B. S. Manjunath in 1999, promising the ability to “retrieve all images that contain regions that have the color of object A, texture of object B, shape of object C, and lie in the upper of the image” (p. 184). It not only uses existing metadata as mentioned above, it uses image analysis to find similar products. In the example picture, a small box is drawn around part of the product, and the engine finds products similar in style or color. The user can then refine by style, color, and other options. This kind of innovative searching is likely to get more and more common.
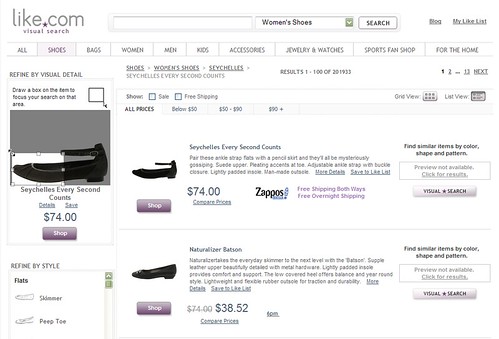
Like.com lets you search by drawing a box around the part of the item you like.
Though full text document analysis is exciting, things really start to get interesting when sites allow for user added metadata and use that data to provide ever better search results. That’ll be the next (and last) part in the series.
Bibliography:
Hodson, T. (2008, March 6). Colourphon: cooking up something interesting. Information Takes Over. Retrieved April 28, 2008, from http://informationtakesover.co.uk/archives/2008/03/06/colourphon-cooking-up-something-interesting/.
Jacobs, C. E., Finkelstein, A., & Salesin, D. H. (1995). Fast multiresolution image querying. Proceedings of the 22nd annual conference on Computer graphics and interactive techniques, 277-286.
Korfhage, R. (1997). Information storage and retrieval. New York: Wiley Computer Pub.
Ma, W. Y., & Manjunath, B. S. (1999). NeTra: A toolbox for navigating large image databases. Multimedia Systems, 7, 184-198.
Pattern, D. (2007, February 1). Michael Stephens = Norman Bates?!? Self-plagiarism is style. Retrieved April 28, 2008, from http://www.daveyp.com/blog/index.php/archives/172/.
Figures
Hi Karin,
Liking your round-up of colour analysis :)
However, I feel compelled to point out that Dave Patterns efforts are entirely asynchronous to our own on colourphon, and it was Dave that reminded me that he had had a play with this before. I would not want, in any way, to steal Dave’s credit :)
Tim
Thanks Tim- I have changed the post. It is sometimes hard to follow the intricacies of who got what from whom on the web.